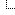

Advertised Sequences and View Counts
A Statistical Inference to Answer an OS-Related Question
Welcome to what might be the one time I actually get a thread I made pinned! But on a more serious note, this was a huge project I did, and will hopefully be useful to other users as well. While I'll try and make it as easy to understand as possible (as I know that there are a multitude of users who don't know statistics), there are a few things that I'll assume that you already know.
Since I have a feeling that a majority of OS users will just TL;DR this, I'll mark important sections like this.
Assumed Knowledge
I will be assuming that you already have knowledge on the things listed below:
Addition, subtraction, multiplication, division, fractions, percentages, variables, linear functions, PEMDAS, inequalities, radicals, and averages/means. Also you should know a little about experiments.
Now that that's out of the way, I'll give you a quick rundown on many of the different terms and symbols that you might find in this thread.
- Population: the entire set of individuals of whom we hope to learn something about. In this case the population would be all sequences on OS.
- Sample: a selected part of a population which we have data on and can use to make inferences about the population.
- Standard Deviation: a measurement of how much the data tends to vary. It's not inaccurate to call it the average variation.
- Standard Error: no, this doesn't mean that an error has been committed. This is when we estimate the standard deviation of something using the data we have at hand.
- Distribution: in this sense, a distribution is how the data are arranged relative to each other and some quantifiable measurement. I can't really explain it very well.
- Unimodal (of a distribution): having one peak.
- Bell-Shaped: https://www.google.com/search?q=bell+sha...9wKVieZGgM
- Normal (of a distribution): https://www.google.com/search?q=normal+d...NHmAY_dmfM:
- Symmetric (of a distribution): having symmetrical look about the mean of the distribution.
- _A=A symbol with a subscript "A" (in this case) refers to the group of sequences that were advertised.
- _N=A symbol with the subscript "N"(in this case) refers to the group of sequences that were not advertised.
- µ= this fancy symbol (pronounced "mew") refers to the mean of a population.
- x̄= this refers to the mean of a sample.
- s= this refers to the standard deviation of a sample.
- n= this simply refers to the number of individuals in a sample.
- µx̄A-x̄N= this one's a bit more complicated. Let's start simple. Every time you select a few individuals from a population and collect data on those individuals, you will produce slightly different results. For example, if I chose 10 people and tested how many push-ups they could do in one sitting, the mean number of pushups they could do would be different from the mean number of pushups another 10 people could do. There is a distribution for this, which shows us the probability of getting different results from different samples. It is called a sampling distribution. This symbol represents the mean of a sampling distribution for the difference in the means: x̄A-x̄N.
- SE(x̄A-x̄N)= this is the standard error for the distribution described in the previous sentence.
- t-model: a giant group of distributions that are all unimodal and bell-shaped. The distributions all vary based on the number of degrees of freedom (it's not necessary to explain what degrees of freedom are).
- Hypothesis test: a test which tests a hypothesis using data.
- 2-sample t-test: a hypothesis test using a t-model.
- Null hypothesis (H0): this is the assumed hypothesis. For a 2-sample t-test, it usually states that there is no difference between the means.
- t-ratio: the test statistic for a hypothesis test. It lets us determine a P-value (below).
- P-value: the probability of getting the data we did from the sample if the null hypothesis was actually true.
- Alternative hypothesis (HA): a small enough P-value will cause us to reject the null hypothesis. The alternative hypothesis is what we accept if we reject the null hypothesis. Depending on what we're looking for, it could say that there is a difference (in general) or it could say the difference in a specific direction. Also: in this case, while it does have the subscript "A," it is not specifically referring to the group of sequences that were advertised.
- Alpha level (α): the boundary that determines when I reject the null hypothesis. If a P-value is smaller than this boundary, then I reject it.
- Confidence interval: this is a tool used to attempt to estimate the true mean of a population using the sample data we have at hand.
- 95% Confidence: to put it simply, if you took a large amount of different samples from a population. You'd expect about 95% of them to capture the true mean of the population with their confidence intervals.
The Question
Hey! Remember This? https://onlinesequencer.net/forum/showth...p?tid=2655
You might've noticed how there were only 15 of the 30 non-drum kit instruments advertised there. If you were especially curious about why, you might've visited my user page and ran into the other 15 sequences. Well, this wasn't your everyday ideas factory. It was an experiment!
You see, many users (me included) self-advertise their sequences on the OS forums. While I can't be sure of why they do it, I can make a few guesses, such as:
- To get feedback from other users
- To organize their music
- To increase the amount of views their sequences get
Does advertising your sequences on the OS forums actually increase their view count?
The Experiment
So, in order to do this, I set up the experiment. This experiment had 2 treatment groups: the first being 15 sequences that were advertised, and the second being the other 15 sequences that weren't. The 30 sequences were made, and each was assigned a number based on the picture below, which you'll probably recognize as the instrument select dropdown menu. Each sequence used 1 instrument different from the instruments of the other sequences. Each sequence was the same note-wise, although maybe not octave wise (as many instruments have different ranges). This was mostly for efficiency purposes.
Each sequence was assigned a number from 1 to 30 based on the instrument they used. I assigned the numbers from top to bottom, ignoring the drum kits (so electric piano would be 1, grand piano would be 2.....music box would be 5, xylophone would be 6, and so on). I then used a random sequence generator, which randomly divided the 30 numbers up into 2 columns. The numbers in the left column represented the advertised sequences, and the numbers in the right column represented the un-advertised sequences. The output is below.
Bias Control
Here's where I got to give my shoutouts to Lucent. Without her these results would've been a lot less reliable. You see, since all of the sequences were identical note-wise, someone would've pointed this out. In order to prevent this, I contacted Lucent and asked if the experiment thread (https://onlinesequencer.net/forum/showth...p?tid=2655) could be made so that no one could reply to this. If someone replied saying that the sequences were all the same then that would definitely effect how (and how much) the sequences would be viewed. If someone did respond, then none of the results from my experiment would've been trustworthy. That's why I had to make sure that it couldn't be replied to.
The Data
Once the experiment was over, the view counts of each sequence were counted up and put into the data table below.
Oh yeah, I forgot to show that there was candy in the data.
Hypotheses
There are 2 hypotheses to a hypothesis test, the null hypothesis and alternative hypothesis. The null hypothesis (H0) is that advertising sequences does not increase the view counts of the sequences advertised (µA=µN or µA-µN=0). The alternative hypothesis (HA) is that advertising sequences does increase the view counts of the sequences advertised (µA>µN or µA-µN>0). The reason that it shows µ is that we want to know if this is true for the population, (as we already know the results for the sample). We can write the hypothesis to show a potential causal relationship because an experiment was performed (There are 2 ways to get data for tests like this, surveying or doing an experiment. An experiment controls for outside factors that can influence data, while surveying can't. So we can imply causation with a well-designed experiment, but not when surveying). You'll see why there is an alternative way of writing hypotheses (using µA-µN) later on.
Conditions
In order to perform a hypothesis test, some conditions must be met.
- Independence among the data.
- Independence between the groups.
- Randomization was used.
- The data came from a population that has a Normal distribution or we have a large sample.
We can check to see if randomization was used. In this case, it was.
Since we don't have a large sample, we'll have to check if it is likely that the data came from a population that is Normally distribution. We do this by making histograms of the data (one histogram for each group). See the histograms below.
Since both histograms are unimodal and symmetric, we are good to proceed with the test. A t-model (with parameters below) to perform a 2-sample t-test for the difference in means.